CS 111 Lecture: The CSV Format and Real-World Data¶
Table of Contents
- Recap: File formats we have seen:
txtandjson - Working with CSV files
- The
csvmodule to work with CSV files
3.1 Understandingcsv.DictReader
3.2 Ex. 1: Calculate population that lives in US capitals
3.3 Understandingcsv.DictWriter
3.4writeheader,writerows,writerow
3.5 Ex. 2: Write names in three columns - Can we sort dictionaries?
- Working with real-world data: Census 2020
5.1 Read the data from the CSV file
5.2 Write most populous US states
5.3 Print least populous US states
5.4 Challenge Problem: Sort in both directions
1. Recap: File Formats we have seen: txt and json¶
We have learned how to read/write text files and load/dump json files.
For both formats, we first open a file for reading and writing. The file object has methods to read and write text content, but not complex data structures such as dictionaries of lists. To do that, we use the special functions json.load and json.dump. Below are examples of how to perform certain operations. They all assume that there is a variable filepath which stores the path to a desired file on our computer.
Read all content of a file
with open(filepath, 'r') as fileObj:
text = fileObj.read()Read one line from a file
with open(filepath, 'r') as fileObj:
line = fileObj.readline()Read all lines from a file
with open(filepath, 'r') as fileObj:
allLines = fileObj.readlines()Write into a file
with open(filepath, 'w') as fileObj:
fileObj.write(someText)Load a JSON object from a file
with open(filepath, 'r') as fileObj:
ourData = json.load(fileObj)Dump a JSON object into a file
with open(filepath, 'w') as fileObj:
json.dump(ourData, fileObj)2. Working with CSV files¶
A CSV (comma-separated values) file is a file within which the values are separated by commas. An appropriate application like Excel can display this data as a table of rows and columns. However, a CSV file is a text file, thus, we can read its content similarly to all text files we have seen so far, with the simple twist that we need to split values at commas. Below is a function that does that:
def tuplesFromFile(filename):
'''Read each line from opened file,
strip white space,
split at commas,
convert as tuple and
return a list of tuples.
'''
with open(filename, 'r') as inputFile:
theTuples = [tuple(line.strip().split(',')) # using list comprehension
for line in inputFile] # implicitely uses .readline()
return theTuples
Let's read the content of the file us-states.csv:
statesData = tuplesFromFile("us-states.csv")
len(statesData)
There are 51 entries, because the first one is the tuple with the column names:
statesData[:4]
There are so many things we can do with this data, but for the moment, we will try something simple: create a CSV file that will look like this:
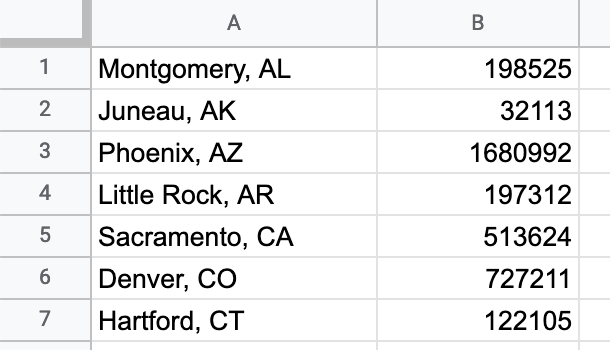
Let's first create the data that looks similar to what the file should contains:
capitals = [] # new list to store tuples of ("Capital, Abbr", Population)
for _,_,abbr,cap,capPop in statesData[1:]: # notice the tuple assignment, since each line is a tuple
# also, we're skipping the row at index 0
capitals.append((f"{cap}, {abbr}", capPop)) # use the f-string to join two values into a string
capitals[:4] # show the first four items
This worked well. Now we can store this data into a CSV file, making sure that we use comma to separate the values, as well as the newline character, '\n'.
with open("capitals-only.csv", "w") as outF:
for item in capitals:
line = f"{item[0]},{item[1]}\n" # create the line to write in the file
outF.write(line)
We can verify the the file was created:
more capitals-only.csv
The data is stored in this new file. Will our function tuplesFromFile be able to correctly read this file?
capitals2 = tuplesFromFile("capitals-only.csv")
capitals == capitals2
We didn't get back the same content that we put in. That is cause for concern. Let's look at each list separately:
capitals[:3]
capitals2[:3]
We can see what happened: our function tuplesFromFile has split the values at the comma, and created a three-element tuple, instead of the two-element tuple we wrote into the file. There are certainly ways to deal with this, but having to write custom-made code everytime we read a new file that we haven't seen before, is not sustainable. This is where Python libraries (or modules) come handy. They contain functions that take into account all possible scenarios, and allow us to abstract away the details of each file.
The json module we have already encountered is such an example, and today we'll look at the csv module.
3. The csv module to work with CSV data¶
The csv module has special functions (known as constructors) that create objects that know how to perform certain operations. These objects are similar to the file objects we learned about a few weeks ago.
csv.reader--> an object that knows how to read a file object line by line. It returns a list of lists.csv.writer--> an object that knows how to write lists into a file object.csv.DictReader--> an object that knows how to read a file object into a list with each element as a dictionary.csv.DictWriter--> an object that knows how to write into a file object a list of dictionaries.
Note: In CS111, we will only focus on csv.DictReader and csv.DictWriter. Students who are interested to learn about the other operations should contact an instructor.
import csv
3.1 Understanding csv.DictReader¶
The csv.DictReader allows us to create an object that knows how to read a line from a CSV file and represent that as a dictionary.
To understand how csv.DictReader works, we will use a very simple CSV file, countries.csv:
country,capital
Canada,Ottawa
Mexico,Mexico City
South Korea,Seoul
Ukraine,KievThere are two steps to follow:
- Create an object of type
csv.DictReaderthat is tied to a file object - Iterate over the new object to force it to do its work of creating dictionaries
with open("countries.csv", "r") as inputFile:
dctReader = csv.DictReader(inputFile) # create an object of the csv.DictReader tied to the file object
dctRows = [dict(row) for row in dctReader] # read the content of dctReader, forcing it to iterate
dctRows
We received a list of dictionaries, where every dictionary represents a row of the CSV table. Let's look at the other objects involved in the block of code:
inputFile # shows the value stored by this variable, an object
dctReader # shows the value stored by this variable, an object
type(inputFile) # the type of our object, this is known as "class name"
type(dctReader) # the type of our object, this is known as "class name"
Thus, we have two different objects here. The first one knows how to open a file for reading, the second one how to read the content of the file line by line and convert each line into a dictionary.
What happens if we don't use an explicit dict conversion?
with open("countries.csv", "r") as inputFile:
dctReader = csv.DictReader(inputFile) # create an object of the csv.DictReader tied to the file object
dctRows = [row for row in dctReader]
dctRows
Python by default creates something called an OrderedDict, which is shown above as a list of tuples. Since this is not something we have learned, we prefer to use dict to convert directly into a dictionary.
3.2 Ex. 1: Find the total population that lives in US capitals¶
In the folder, you'll find the file "us-capitals.csv", which looks like this:
"Capital, Abbr",Population
"Montgomery, AL",198525
"Juneau, AK",32113
"Phoenix, AZ",1680992
"Little Rock, AR",197312
"Sacramento, CA",513624Your task is to write a function that given the name of the file as a parameter, it will return the total population that lives in all these US capitals.
def totalCapitalsPopulation(filename):
"""This fuction should:
1. read the content of the given CSV file as a list of dictionaries
2. Use an accumulator variable to calculate the total population while
iterating over the csv.DictReader object.
Note: It is possible to solve this problem in at least two ways, one of which
uses list comprehension.
"""
# Your code here
totalPop = 0 # accumulator variable
with open(filename, 'r') as fileObj:
dctReader = csv.DictReader(fileObj)
for row in dctReader:
totalPop += int(row['Population'])
return totalPop
Test the function:
totalCapitalsPopulation("us-capitals.csv") # Expected value: 13584723
OPTIONAL: Alternate solution with list comprehension
Python has a useful built-in function, sum, which can be used to get the sum of all numbers in a list. For example:
sum([1,2,3,4,5])
Write below the alternate solution with list comprehension. It needs to use the function sum.
def totalCapitalsPopulationLC(filename):
"""An alternate solution that uses list comprehension.
It makes use of the function sum.
"""
# Your code here
with open(filename, 'r') as fileObj:
dctReader = csv.DictReader(fileObj)
totalSum = sum([int(row['Population']) for row in dctReader])
return totalSum
totalCapitalsPopulationLC("us-capitals.csv") # Expected value: 13584723
3.3 Understanding DictWriter¶
How to write into a CSV file? You already have created comma-separated files in the past. We also saw one example in this notebook:
capitals = [('Montgomery, AL', '198525'),
('Juneau, AK', '32113'),
...
]
with open("capitals-only.csv", "w") as outF:
for item in capitals:
row = f"{item[0]},{item[1]}\n" # create the line to write in the file
outF.write(row)But, this created the issue of how to deal with values that contain commas. This is why we will now discuss csv.DictWriter, which resolves this issue and many others.
Let's say we are given a list of dictionaries (csv.DictWriter only works with a list of dictionaries):
oscarMovies = [{'title': 'CODA', 'year': 2022},
{'title': 'Nomadland', 'year': 2021},
{'title': 'Parasite', 'year': 2020}]Below is a code snippet to write this list of dicts as a CSV file. It uses this structure:
- Opens a new file for writing
- Creates a
csv.DictWriterobject tied to the file object - Writer the header of the file (containing the column titles
- It writes all the rows
oscarMovies = [{'title': 'CODA', 'year': 2022},
{'title': 'Nomadland', 'year': 2021},
{'title': 'Parasite', 'year': 2020}]
columns = oscarMovies[0].keys() # find the names of the columns
with open('oscarWinners.csv', 'w') as outFile:
dctWriter = csv.DictWriter(outFile, fieldnames=columns)
dctWriter.writeheader() # no need for argument, it was provided above
dctWriter.writerows(oscarMovies)
Let's check the file:
more oscarWinners.csv
Swapping Columns
csv.DictWriter has a cool feature. It allows us to easily swap the order of columns, through its parameter 'fieldnames'. Concretely:
columns2 = ['year', 'title']
with open('oscarWinners2.csv', 'w') as outFile:
dctWriter = csv.DictWriter(outFile, fieldnames=columns2) # new variable, columns2
dctWriter.writeheader()
dctWriter.writerows(oscarMovies) # list of dicts stays the same
more oscarWinners2.csv
We successfully rewrote the structure of our file with very little effort. That is the power of using Python libraries.
3.4 writeheader, writerows, writerow¶
In the previous example, we used two methods of the csv.DictWriter object:
writeheader--> writes the first row of the file, containing the column nameswriterows--> writes all the rows, using the data from the list of dictionaries
The latter method is very handy when we already have the list of dictionaries. But sometimes we don't. Sometimes we might be creating a dictionary as we go. In this case, we can use writerow instead. Let's see a simple example:
# writing a file with names and alteregos of famous superheroes
with open('superheroes.csv', 'w') as outFile:
dctW = csv.DictWriter(outFile,
fieldnames=['name', 'alterego'])
dctW.writerow({'name': 'Superman', 'alterego': 'Clark Kent'})
dctW.writerow({'name': 'Scarlet Witch', 'alterego': 'Wanda Maximoff'})
dctW.writerow({'name': 'Wonderwoman', 'alterego': 'Diana Prince'})
more superheroes.csv
We left out the method writeheader intentionally, for you to see that if we don't explicitely call it, the csv.DictWriter object will not write the names of the columns, even though it has access to them.
IMPORTANT: If you forget to use .writeheader() and then read a CSV file with csv.DictReader, it will use the first row as the list of column names.
with open('superheroes.csv', 'r') as inputFile:
dctR = csv.DictReader(inputFile)
rows = [dict(row) for row in dctR]
rows
As you can see, this is not what we want.
Remember this example, so that you don't forget to add the header for the file.
3.5 Ex. 2: Write names in three columns¶
You are given an arbitrarely long list of names that are strings composed of a first, middle, and last name. Here is an example:
scientists = ['Maria Gaetana Agnesi',
'Marie-Anne Pierrette Paulze',
'Mary Fairfax Somerville'
'Elizabeth Garrett Anderson',
...
]Use csv.DictWriter to write the content of this list as a CSV file with three columns as shown below. Make use of the methods writeheader, and writerow within a for loop.
first,middle,last
Maria,Gaetana,Agnesi
Marie-Anne,Pierrette,Paulze
Mary,Fairfax,Somerville
Elizabeth,Garrett,AndersonThis is not straightforward, because we are not given a list of dictionaries, as in previous examples. How can we easily create dictionaries? We show some examples below.
The functions dict and zip¶
We saw in the lecture about dictionaries that Python has a built-in function, dict, which can create a dictionary from a list of lists or a list of tuples. Here is an example:
fruitsDct = dict([('apple', 2.99), ('banana', 1.49), ('orange', 3.29)])
fruitsDct
What made this easy was the fact the we already had a list of tuples. What if our data is not already in this form? For example, we can have two separate lists:
fruits = ['apple', 'banana', 'orange']
prices = [2.99, 1.49, 3.29]
How do we create a list of pairs here? We can use list comprehension!
fruitPrices = [(fruits[i], prices[i]) for i in range(len(fruits))]
fruitPrices
Is there an easier way to do this? Yes, the built-in function zip, which does what the word says, zips together two lists (or more), element-wise.
zip(fruits, prices) # creates an object for performing the zipping
list(zip(fruits, prices)) # forces zip to do the work
dict(zip(fruits, prices)) # create a dict from the zipped lists
Now that we know about how dict and zip work, we can solve our problem more easily.
# these are some early women scientists (18th and 19th century)
scientists = ['Maria Gaetana Agnesi',
'Marie-Anne Pierrette Paulze',
'Mary Fairfax Somerville',
'Elizabeth Garrett Anderson'
]
def writeNamesInColumns(namesList, filename):
"""For simplicity, assume all names have all three parts.
We leave it as an optional excersise for students to deal with names that
don't have a middle part.
You must use csv.DictWriter!
"""
columns = ['first', 'middle', 'last']
# Your code here
with open(filename, 'w') as outFile:
dctW = csv.DictWriter(outFile, fieldnames=columns)
dctW.writeheader()
for name in namesList:
nameparts = name.split()
dctRow = dict(zip(columns, nameparts))
dctW.writerow(dctRow)
Let's test the function:
writeNamesInColumns(scientists, 'scientists.csv')
more scientists.csv
It created the file that we intended.
4. Can we sort dictionaries?¶
Does it make sense to sort a dictionary? What happens if we try to do so?
fruitColors = {"banana": "yellow", "kiwi": "green",
"grapes": "purple", "apple": "red",
"lemon": "yellow", "pomegranate": "red"}
sorted(fruitColors)
We didn't get an error, but all that was sorted were the keys of the dictionary.
Try to predict what we will see in the following lines:
sorted(fruitColors.values())
sorted(fruitColors.items())
sorted(fruitColors.keys())
In conclusion we can say:
- we can sort the list of the keys
- we can sort the list of the values
- we can sort the list of the items (the (key,value) pairs)
but not the dictionary itself. Meanwhile, we might be able to sort a list of dictionaries, though it's not straightforward.
First, we need to convert our dictionary of fruitColors into a list of dictionaries, all with the same structure:
# Create a list of dictionaries
fruitColorLst = []
for fruit, color in fruitColors.items():
fruitColorLst.append({'fruit': fruit,
'color': color})
fruitColorLst
Can we sort this list?
sorted(fruitColorLst)
It is not working, becuase Python doesn't have rules for comparing dictionaries, the way that there are rules for comparing strings and tuples (as we have learned when we discussed sorting of sequences). That means, we would have to provide the key parameter to tell Python how to compare the items of this list of dictionaries for sorting.
def byFruit(fruitDct):
"""Helper function to be used in sorted."""
return fruitDct['fruit']
sorted(fruitColorLst, key=byFruit)
Your Turn: Do the same, but by sorting by color.
# Sort fruitColorLst by fruit color
# Your code here
def byColor(fruitDct):
"""Helper function to be used in sorted."""
return fruitDct['color']
sorted(fruitColorLst, key=byColor)
Now that we learned how to sort list of dictionaries, we will put this in practice by reading CSVs, sorting them by various columns, and writing them in CSV files.
5. Working with real-world data: Census 2020¶
In Section 2 of this notebook, we used the file us-states.csv, which contained information about each state, such as:
State,StatePop,Abbrev.,Capital,CapitalPop
Alabama,4921532,AL,Montgomery,198525
Alaska,731158,AK,Juneau,32113
Arizona,7421401,AZ,Phoenix,1680992
Arkansas,3030522,AR,Little Rock,197312
California,39368078,CA,Sacramento,513624
Colorado,5807719,CO,Denver,727211These are real-world data retrieved from the Census website. In the United States, representation in Congress (House of Representatives) is decided from changes in states' population every ten years. Using the skills that you have learned in the past few lectures, you should be able to write Python code to answer questions with Census data:
- Which are the most populated US states? Rank the data in that order.
- Which are the least populated US states? Rank the data in that order.
- Which US state capitals are the most populated? Rank the data in that order.
- Which US state capitals are the least populated? Rank the data in that order.
- What percentage of each US state’s population lives in the state capital? Rank the data by that percentage from the largest to the smallest.
You will write code to read the CSV file, sort it in different ways, and then write the results in new CSV files.
5.1 Read the data from the CSV file¶
We are providing you with the code of reading a CSV file as a list of dictionaries, so that you can focus on sorting.
import csv
# Read content of CSV file as a list of dictionaries
with open("us-states.csv", 'r') as inputF:
dctReader = csv.DictReader(inputF)
stateDctList = [dict(row) for row in dctReader]
len(stateDctList)
Look up an item of this list:
stateDctList[0]
Important: All values in the dictionaries are strings, even the numbers. This is because the CSV format is fundamentally a text format. That means that if we want to use the numerical values, we need to convert them to integer or floats, as appropriate.
5.2 Rank US States by Population (and write them into a file)¶
How to approach this problem? Here is the algorithm for it:
- We will create a helper function
byStatePop, which, given a dictionary with state data (one row from our file), returns the appropriate value. We will convert this value into an integer value. - We will apply the
sortedfunction to the list of dictionaries of state data (stateDctList), using the key parameter that has as valuebyStatePop. - We will look at the results, in which way are they sorted?
- We will change the function parameter
reverseto change the order of sorting. - We will print out the results (to show how we generated results for Slides 15 & 16)
- You will code a function to write the results into a CSV file
def byStatePop(stateDct):
"""Helper function to be used in sorted."""
return int(stateDct['StatePop'])
# Sort the list, save it in a variable, check its three first values
sortedStates1 = sorted(stateDctList, key=byStatePop)
sortedStates1[:3]
We can see that it's not in the right order, so we need to use reverse in the sorted function:
sortedStates1 = sorted(stateDctList, key=byStatePop, reverse=True)
sortedStates1[:3]
We'll use below an advanced syntax for the f-string, that adds a comma to the integer representation of population values. Do not worry about it, we want you simply to be aware that f-string is very powerful.
# Let's print out the top 6 most populated countries (as shown in Slide 15)
print("Top six most populated US states:\n")
for stateDct in sortedStates1[:6]:
print(f"{stateDct['Abbrev.']} -> {int(stateDct['StatePop']):,}")
Your Turn:
Now it's your turn. Write the function writeSortedFile, which takes two parameters:
- a list of sorted dictionaries
- the name of the file and writes the content into CSV file. Your function call will look like this:
writeSortedFile(sortedStates1,
'statesByPopulation_desc.csv')The function doesn't return anything. Its side effect is to create the CSV file with the data.
def writeSortedFile(sortedList, # contains a list of sorted dictionaries
filename # the filename
):
"""Opens a file for writing,
finds the list of fields (the keys of each dictionary in the list)
creates a DictWriter object (don't forget the fieldnames)
writes the header,
writes the rows.
"""
# Your code here
with open(filename, 'w') as outputFile:
columns = sortedList[0].keys()
dctW = csv.DictWriter(outputFile, fieldnames=columns)
dctW.writeheader()
dctW.writerows(sortedList)
Let's call the function:
writeSortedFile(sortedStates1,
'statesByPopulation_desc.csv')
Let's see the created file:
more statesByPopulation_desc.csv
What if we want to write only two columns and not all of them?
We can pass to fieldnames parameter a subset of the columns, but Python will complain about the dictionary to write having more keys. However, there is an additional parameter that will force Python to drop this complain:
dctW = csv.DictWriter(outputFile,
fieldnames=columns,
extrasaction='ignore' # ignore keys not in columns
)Optional Task
Modify the function writeSortedFile to only save some of the columns in the CSV file.
def writeSortedFile(sortedList, # contains a list of sorted dictionaries
columns, # contains a partial list of the columns
filename # the filename
):
"""Opens a file for writing,
creates a DictWriter object,
writes the header,
write the rows
"""
# Your code here
with open(filename, 'w') as outputFile:
dctW = csv.DictWriter(outputFile,
fieldnames=columns,
extrasaction='ignore'
)
dctW.writeheader()
dctW.writerows(sortedList)
writeSortedFile(sortedStates1,
['Abbrev.', 'StatePop'],
'statesByPopulation_desc.csv')
more statesByPopulation_desc.csv
5.3 Print the least populated US States¶
This is very similar to the first part of the Section 5.2. Write code that prints out the following six states (the least populated in the US):
Top six least populated US states:
WY -> 582,328
VT -> 623,347
AK -> 731,158
ND -> 765,309
SD -> 892,717
DE -> 986,809# Your code here
sortedStates2 = sorted(stateDctList, key=byStatePop)
print("Top six least populated US states:\n")
for stateDct in sortedStates2[:6]:
print(f"{stateDct['Abbrev.']} -> {int(stateDct['StatePop']):,}")
5.4 Challenge Problem: sort in both directions¶
While the notebook makes it easy to solve problems, the solution is scattered in multiple cells. What we would like to have is a series of functions that can be put together to solve a problem once and for all, and then just use the solution with different arguments.
In this task, you will try to write a single function writeSortedColumns, which can be used to solve both questions we encountered above (sort by the most or least populated states, and show a subset of columns). Concretely, the function should take these parameters:
- it takes the name of a CSV file that needs to be sorted
- it takes a sorting order (a boolean that is True or False)
- it takes a list of columns that specify a subset of columns to show
The function should create a new CSV file to contain the sorted columsn. It should use as many helper functions as possible, for example, a function that creates a new file name which combines the existing file name with the words: "ascending" or "descending" (depending on the sorting direction).
# Write the helper function to change the file name
# Your code here
def createFileName(filename, reverseOrder):
"""Helper function to create a new filename.
"""
name, ext = filename.split('.')
if reverseOrder == True:
extra = "descending"
else:
extra = "ascending"
return f"{name}_{extra}.{ext}"
createFileName("us-states.csv", True)
createFileName("us-states.csv", False)
def writeSortedColumns(filename, reverseOrder, columnsList):
"""
A function that given a CSV filename will:
- read its content
- sort it
- create a new filename based on sorting order
- write the sorted rows in the new file
"""
# Your code here
# Step 1: Read the file
with open(filename, 'r') as inputFile:
dctReader = csv.DictReader(inputFile)
rowsDctList = [dict(row) for row in dctReader]
# Step 2: Sort the list of dicts
sortedRows = sorted(rowsDctList, key=byStatePop, reverse=reverseOrder)
# Step 3: create new file name
newfilename = createFileName(filename, reverseOrder)
# Step 4: write a new CSV file
with open(newfilename, 'w') as outputFile:
dctWriter = csv.DictWriter(outputFile,
fieldnames=columnsList,
extrasaction='ignore'
)
dctWriter.writeheader()
dctWriter.writerows(sortedRows)
Test the function to do the descending order (from the most populous to the least):
writeSortedColumns("us-states.csv", True, ['Abbrev.', 'StatePop'])
more us-states_descending.csv
Test the function to do the ascending order (from the most populous to the least):
# we are changing the arguments for the 2nd and 3rd parameter
writeSortedColumns("us-states.csv", False, ['State', 'StatePop'])
more us-states_ascending.csv
Additional Challenge
How would you need to modify the function writeSortedColumns, so that instead of sorting by state population, it sorts by capital population?
This is all for today!