Lecture: Directories and File System Operations¶
Table of Contents
1. Depiction of a File Tree¶
The folder where your notebook resides can be displayed as a file tree that looks like the image below. It's a partial view of the folder, missing the subfolders books and books2.
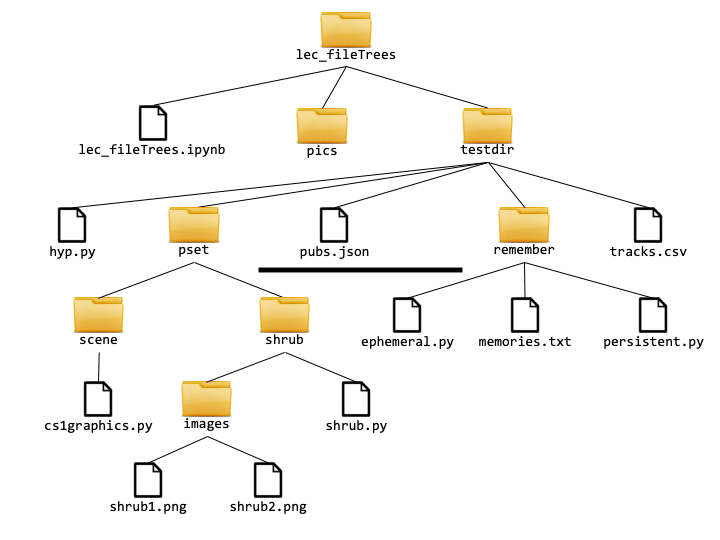
A file tree is defined as:
a file (a leaf of the tree). In the above tree, files are represented by the document icon.
a directory (a.k.a. folder, an intermediate node of the tree) containing zero or more file trees. In the above tree, directories are represented by the folder icon.
The top node of the tree (in this case, the folder named lec_fileTrees) is called the root of the tree.
Tree-shaped structures consisting of nodes that branch out to subtrees that terminate in leaves are common in computer science. We focus on file trees in this lecture because everyone is familiar with them and it is important to understand their structure when working with data and your own computers.
We can also use a text-based representation to display file trees as well. Here is one such example below:
.
|-- .data
|-- books
| |-- jane_austen
| | |-- Pride_and_Prejudice.txt
| | |-- Mansfield_Park.txt
| |-- charlotte_perkins_gilman
| | |-- The_Yellow_Wallpaper.txt
| | |-- Women_and_Economics.txt
| |-- oscar_wilde
| | |-- The_Importance_of_Being_Earnest.txt
| | |-- The_Picture_of_Dorian_Gray.txt
|-- books2
| |-- zora_neale_hurston
| | |-- Three_Plays.txt
| | |-- Poker!.txt
| |-- charlotte_bronte
| | |-- Jane_Eyre.txt
| | |-- The_Professor.txt
| |-- lewis_carroll
| | |-- Alice_in_Wonderland.txt
| | |-- Symbolic_Logic.txt
| | |-- Through_the_Looking-Glass.txt
|-- lec_fileTrees.ipynb
|-- pics
| |-- fileListingWithHiddenFiles.png
| |-- fileTreeRootedAtTestdir.png
| |-- fileTree.png
| |-- fileListingWithoutHiddenFiles.png
|-- testdir
| |-- remember
| | |-- persistent.py
| | |-- memories.txt
| | |-- ephemeral.py
| |-- hyp.py
| |-- pubs.json
| |-- pset
| | |-- scene
| | | |-- cs1graphics.py
| | |-- shrub
| | | |-- images
| | | | |-- shrub2.png
| | | | |-- shrub1.png
| | | |-- shrub.py
| |-- .numbers
| |-- tracks.csv
2. Operating System (OS) Commands in the Notebook¶
In the lecture slides we introduced several OS commands that are used in the Terminal. It turns out that we can directly use certain OS commands within the Jupyter notebook as well, to figure out information about files and folders.
pwd: print working directorycddirName : change the working directory to dirNamecd ..: change the working directory to the parent of the current working directory. (In general,..means "parent of the current directory" and.means "the current directory".)
ls: list the contents of working directorylsdirName : list the contents of directory dirName- the
-aflag tolsstands for all and includes hidden files (begin with a dot) - the
-lflag tolsputs each file on a line with extra information (size, timestamp, etc) - the
-aand-lflags can be combined as-al
Let's try them below to see the results.
pwd
ls
Let's change the current directory, moving to the folder testdir:
cd testdir
The Jupyter command returns the absolute path for the new folder, but in the Terminal this is not the case. We need to use pwd:
pwd
ls
ls -a
ls -al
cd ..
IMPORTANT: All these command lines can be used in the Terminal application in a Mac computer to navigate folders in the computer. Alternatively, they are performed via point-and-click operations in the Finder application. Windows uses similar (but slightly different) commands from the Command Prompt.
3. Python os commands¶
Via the os module, Python provides a way to manipulate the directories and files in a file system. To use these features, we first need to import the os module:
import os
(a) Get working directory: os.getcwd¶
The os.getcwd function returns the current working directory as a string.
os.getcwd()
(b) List directory: os.listdir¶
The os.listdir function returns a list of all files/directories in the argument directory.
os.listdir(os.getcwd())
So-called "dot files" whose names begin with the '.' character are special system files that are often hidden by the operating system when displaying files. We will tend to ignore them. Note that "dot files" do not include . (the current directory) or .. (the parent directory).
Depending on the settings for your computer's file browser (e.g., Finder on a Mac), you might or might not see dot files explicitly listed in the file browser. For example, here's a version of a Mac Finder window where hidden files are shown:

And here's a version of a Mac Finder window where dot files are not shown. Note that by default newer versions of Finder will not show .DS_store files:

Let's see more examples of os.listdir, which can be used with relative paths of our own making:
os.listdir('testdir')
os.listdir('testdir/remember')
os.listdir('testdir/pset')
os.listdir('testdir/pset/scene')
os.listdir('testdir/pset/shrub')
To note: We create relative paths as strings in which folder names are concatenated with the slash character.
YOUR TURN: Below, write a command that lists the content for the subfolder "images".
The expected result is ['shrub1.png', 'shrub2.png'].
# Your code here
os.listdir('testdir/pset/shrub/images')
What happens if the os.listdir is given the name of a nondirectory file or a nonexistent file?
os.listdir('testdir/hyp.py')
os.listdir('remember') # Not a subdirectory of the connected directory
(c) Does this path exist?¶
The os.path.exists function determines whether the given name denotes a file/directory in the filesystem.
os.path.exists('testdir/remember/memories.txt')
os.path.exists('testdir/remember')
os.path.exists('catPlaysPiano.jpg')
os.path.exists('remember')
Note that the search for a file/directory begins in the working directory, which in the above examples is the lec_fileTrees directory. This is why os.path.exists('testdir/remember') is True but os.path.exists('remember') is False.
YOUR TURN: How would you check that the file cs1graphics.py is in the sample file tree?
# Your code here
os.path.exists('testdir/pset/scene/cs1graphics.py')
(d) Determine file or directory status¶
The os.path.isfile and os.path.isdir functions determine whether the given name is a file or directory, respectively. They both return false for a nonexistent file/directory name.
os.path.isfile('testdir/remember/memories.txt')
os.path.isdir('testdir/remember/memories.txt')
os.path.isfile('testdir/remember/')
os.path.isdir('testdir/remember/')
os.path.isfile('remember')
os.path.isdir('remember')
YOUR TURN: Verify that shrub1.png is a file, using the correct path.
# Your code here
os.path.isfile('testdir/pset/shrub/images/shrub1.png')
YOUR TURN: Verify that scene is a directory, using the correct path.
# Your code here
os.path.isdir('testdir/pset/scene')
(e) Creating a path with os.path.join¶
We can use os.path.join to join to strings that contain parts of the path. We often need to do this together with os.listdir, which only shows the names of the contained files and directories without their relative paths.
root = 'testdir'
for name in os.listdir(root):
print(name)
But, joining the root folder with the file name gives the entire relative path for a file/folder:
root = 'testdir'
for name in os.listdir(root):
print(os.path.join(root, name))
We could instead use string concatenation via + to combine path elements, but os.path.join is more convenient for handling the slashes that separate path components.
os.path.join('testdir/', 'remember/', 'memories.txt')
os.path.join('testdir', 'remember', 'memories.txt')
'testdir' + '/' + 'remember' + '/' + 'memories.txt'
YOUR TURN: Modify the above for loop to print out the relative paths of only the directories in testdir. You'll need to use one of the functions we learned in this section, in addition to os.path.join:
# Your code here
root = 'testdir'
for name in os.listdir(root):
pathName = os.path.join(root, name)
if os.path.isdir(pathName):
print(pathName)
(f) Getting the last component of path with os.path.basename¶
os.path.basename returns the last component in a file path.
os.path.basename('testdir/remember/memories.txt')
os.path.basename('testdir/remember')
os.path.basename('testdir/remember/')
(g) Getting the size of files and folder with os.path.getsize¶
A file has a size measured in bytes. For a folder, the size only refers to some bookkeeping information; it does not refer to the total size of the files in the folder!
os.path.getsize("testdir/remember/ephemeral.py")
os.path.getsize("testdir/remember/memories.txt")
os.path.getsize("testdir/remember/persistent.py")
os.path.getsize("testdir/remember")
Note that 160 is less than (379 + 80 + 1634); it is unrelated to the sizes of the files in the remember directory!
os.path.getsize("testdir/tracks.csv")
os.path.getsize("testdir")
4. Exercise 1: Relative Paths¶
Write a for loop that will print (1) the relative path name of each element in the testdir folder along with (2) its size. The solution should look like this (note that your order may be different):
testdir/.DS_Store 6148 # This might or might not appear, depending on your operating system.
testdir/.numbers 21
testdir/hyp.py 94
testdir/pset 170
testdir/pubs.json 107062
testdir/remember 170
testdir/tracks.csv 18778Note: this is trickier than it might first appear. Mastering this pattern is essential for writing functions that manipulate file trees (see the next section).
# Your code here
folder = 'testdir'
for name in os.listdir(folder):
wholeName = os.path.join(folder, name)
print(wholeName, os.path.getsize(wholeName))
5. Exercise 2: printSubFolders¶
Write a function that given some path to a folder, prints all subfolders contained in that folder.
def printSubFolders(folderPath):
"""
Given a path to a folder, print the names of all subfolders
contained in the folder.
"""
# Your code here
for f in os.listdir(folderPath):
if os.path.isdir(os.path.join(folderPath, f)):
print(f)
printSubFolders("testdir") # should print pset and remember
printSubFolders("testdir/remember") # should print nothing
printSubFolders("testdir/pset") # should print shrub and scene
6. Reading from File Trees¶
Understanding file trees is essential when working with large data because data tends to be split across many files and folders. Below is a file tree of some data we will work with in the coming examples. The folder books contains folders of authors. Each author folder contains complete books found from Project Gutenberg. We will use the next series of examples to analyze some properties of all the books. To do so we will need to read multiple files spread across a file tree. Below is a file tree of the books folder.
books
|-- jane_austen
| |-- Pride_and_Prejudice.txt
| |-- Mansfield_Park.txt
|-- charlotte_perkins_gilman
| |-- The_Yellow_Wallpaper.txt
| |-- Women_and_Economics.txt
|-- oscar_wilde
| |-- The_Importance_of_Being_Earnest.txt
| |-- The_Picture_of_Dorian_Gray.txt
There is also another folder containing books called books2. It follows the same structure in that subfolders of books2 are authors that contain books.
6.1 Understanding books¶
The books folder contains three subfolders as shown below using os.listdir. Those subfolders are author names.
os.listdir("books")
Each author folder contains files for each book of that author.
os.listdir("books/jane_austen")
Let's revisit how to read from a file. To read a file, we use a with block. Remember the with block will automatically close the file when we are done. Below is a function that takes a filepath and opens the file at that file path. We can use open with any valid file path as long as the file path is a file. If not, we will raise an error.
Note: We want to remove the newline character from string returned by .readline(). The method .strip() will not work here because it will remove all whitespace before and after each line. This would remove things such as tabbing. Since the last character of each line will always be a newline character, we can simply slice up to the last character to remove it.
def printBookLines(bookPath, numLines):
"""
Given the path of a text file and a number of lines,
print that many lines from the file.
"""
with open(bookPath, "r") as book:
for _ in range(numLines):
print(book.readline()[:-1])
printBookLines("books/jane_austen/Pride_and_Prejudice.txt", 10)
printBookLines("books", 10) # error because `books` is a folder and not a file
6.2 Getting the file paths of subfiles and folders¶
Below is a function that returns a list of all the paths to each book. This will be a critical helper function in the next series of exercises. How does it work? It requires a nested loop with the outer loop cycling through all the author folders and the inner loop going through each book of the author folders. Notice that we filter out all files and hidden files/folders. This removes the pesky .DS_store for example that is common in MacOS file systems.
def getBookPaths(rootFolder):
"""
Given a path, return a list of all paths to files in the subfolders.
This is an accumulation problem.
"""
paths = []
for author in os.listdir(rootFolder):
authorFolderPath = os.path.join(rootFolder, author)
# filter out hidden files and non-directories like .DS_Store
if os.path.isdir(authorFolderPath) and author[0] != ".":
for book in os.listdir(authorFolderPath):
if not book.startswith('.'): # filter out hidden files
bookPath = os.path.join(authorFolderPath, book)
paths.append(bookPath)
return paths
getBookPaths("books")
getBookPaths("books2")
6.3 largestBookSize¶
Using the function we wrote above, we can write a function called largestBookSize that returns the largest book in bytes from the books folder. Here we can go through all the paths and use os.path.getsize to get the size of each book.
def largestBookSize(rootFolder):
"""
Traverse all subfolders, find book with the largest size.
"""
largestBook = ("", 0) # a tuple to store a file title and its size
paths = getBookPaths(rootFolder)
for bookPath in paths:
bookSize = os.path.getsize(bookPath)
book = os.path.basename(bookPath) # the last part of the path is the book file name
if bookSize > largestBook[1]:
largestBook = book, bookSize
return largestBook
largestBookSize("books")
largestBookSize("books2")
7. Exercise 3: totalLines¶
Below write a function that gets the total number of lines of all the books from a folder structured like the books folder (i.e., it should work for both books and books2). Your function should return a list of tuples where each tuple should contain the file name of the book and the number of lines. Below is the sample output of the function when called with books. Your function should take one argument: the root folder of a book directory. Resist the urge to use the len function would require you to read in all the lines of the book at once. This requires a lot of memory. Instead loop over each line of the book and increment a counter to get the total number of lines.
[('The_Picture_of_Dorian_Gray.txt', 8908),
('The_Importance_of_Being_Earnest.txt', 4269),
('Women_and_Economics.txt', 10132),
('The_Yellow_Wallpaper.txt', 1225),
('Mansfield_Park.txt', 16054),
('Pride_and_Prejudice.txt', 14580)]Note: You should use getBookPaths to get the list of file paths for all books.
def totalLines(rootFolder):
"""
Given the path to a folder such as 'books' or 'books2',
keep track of the total number of lines in all encountered files.
This is an accumulator function.
"""
# Your code here
bookLines = []
paths = getBookPaths(rootFolder)
for bookPath in paths:
bookName = os.path.basename(bookPath)
with open(bookPath) as book:
lineCount = 0
for line in book:
lineCount +=1
bookLines.append((bookName, lineCount))
return bookLines
totalLines("books")
totalLines("books2")
8. Exercise 4: totalSentences¶
Write a function called totalSentences that takes a path to a book folder like books and returns a list of tuples where each tuple contains the name of the book and the number of sentences in the book. How do we determine the number of sentences in a book? One simple, though potentially inaccurate way, is to simply count the number of periods in the book. This may not be the most accurate because the period could be used in formatting at the beginning and end of the book. Other books can use punctuation (or the lack thereof) in interesting ways like Faulkner's "The Sound and the Fury".
We will take the simple approach and simply count the number of periods. You can use the string method .count which counts the number of instances of a substring in some other string. For example, "AbraAbra".count("Abra") evaluates to 2.
Here is the output of totalSentences("books"):
[('The_Picture_of_Dorian_Gray.txt', 6049),
('The_Importance_of_Being_Earnest.txt', 3119),
('Women_and_Economics.txt', 4390),
('The_Yellow_Wallpaper.txt', 516),
('Mansfield_Park.txt', 7118),
('Pride_and_Prejudice.txt', 6402)]def totalSentences(rootFolder):
"""
Similar to the function totalLines, but instead of lines,
it counts sentences.
"""
# Your code here
bookSentCount = []
paths = getBookPaths(rootFolder)
for bookPath in paths:
bookName = os.path.basename(bookPath)
with open(bookPath) as book:
count = 0
for line in book:
count += line.count(".")
bookSentCount.append((bookName, count))
return bookSentCount
totalSentences("books")
totalSentences("books2")
9. Exercise 5: wordOccurrences¶
Write a function called wordOccurrences that counts the number of times a word appears in each book. wordOccurrences should take a path to folder structured like books and a word to look for. Counting the number of occurrences of a word is not an easy task. There are many factors to consider:
- Should case matter? Maybe not for most words but probably for proper nouns.
- Should plurality matter for nouns? Is
"water"the same as "waters"? - How do we define the surrounding criteria for a word? For example, if we are searching for occurrences of
"he", we need to be careful to not count words like"the". An easy heuristic is to mandate that a word have a space on either side. This would ensure we do not count words like"the"for"he". However, what if the word is the last word of a sentence? Then it would have punctuation and not spaces but should count as a word.
To make our lives simpler, we will define the occurrence of a word as having a space on either side and ignore case. Of course, this will not be a perfect word counter. As a challenge see if you can define better criteria and implement it in code for a more robust word counter.
Below is the sample output from wordOccurrences("books", "she"):
[('The_Picture_of_Dorian_Gray.txt', 312),
('The_Importance_of_Being_Earnest.txt', 40),
('Women_and_Economics.txt', 239),
('The_Yellow_Wallpaper.txt', 21),
('Mansfield_Park.txt', 1671),
('Pride_and_Prejudice.txt', 1368)]def wordOccurrences(rootFolder, word):
# Your code here
wordCount = []
testWord = " " + word.lower() + " " # word has to have spaces around it; also ignore case
paths = getBookPaths(rootFolder)
for bookPath in paths:
bookName = os.path.basename(bookPath)
with open(bookPath) as book:
count = 0
for line in book:
if testWord in line.lower():
count += 1
wordCount.append((bookName, count))
return wordCount
wordOccurrences("books", "she")
wordOccurrences("books", "he")
wordOccurrences("books", "water")
10. Super Challenge: Create a File Tree¶
Write a function called fileTree that prints out a text-based version of a file tree. For example, here is the output of the file tree on the books folder.
books
|-- jane_austen
| |-- Pride_and_Prejudice.txt
| |-- Mansfield_Park.txt
|-- charlotte_perkins_gilman
| |-- The_Yellow_Wallpaper.txt
| |-- Women_and_Economics.txt
|-- oscar_wilde
| |-- The_Importance_of_Being_Earnest.txt
| |-- The_Picture_of_Dorian_Gray.txt
This is a real challenge and unlike any programming paradigm you have seen so far though it does not require any new tools or syntax. We would not expect to give you any question like this on an exam or even problem set without a lot of structure/scaffolding. But challenges are good!
The trick is to use a list that keeps track of all the file paths and grows as new folders are discovered. The list should contain tuples of file paths and "levels". Notice how the file tree becomes indented as it is nested. You will need some way to keep track of that information.
def fileTree(rootFolder):
"""
A function that given the path of a root folder, prints out the
it's content as a 'file tree'. Nothing is returned, the function
only prints lines with information.
"""
# Your code here
paths = [(rootFolder, 0)]
levelStr = "| "
fileStr = "|-- "
while len(paths) > 0:
path, level = paths.pop()
name = os.path.basename(path)
if level == 0:
print(name)
else:
print((level - 1) * levelStr + fileStr + name)
if os.path.isdir(path):
for sub in os.listdir(path):
paths.append((os.path.join(path, sub), level + 1))
fileTree("books")
fileTree("books2")
fileTree(".")
That's all for today's notebook!