Our plan for today
- Web APIs general overview
- last.fm: getting similar songs
- google maps: getting directions
Set up
Download thelab12_programs folder from the cs server. Rename it to be yours. Start Canopy. Ready to roll.
- Sravana shared this great overview document via the cs111 google group.
- Web API lecture notes 1/2
- Web API lecture notes 2/2
Steps to generate a web page with results
- Use http to make a request for data, save results (import requests)
- Examine the results to understand how the information is structured (import json)
- Iterate through the dictionaries/lists of python to extract the information of interest
- Pop the items of interest into an HTML template (import jinja2)
- View the HTML page in a browser (import webbrowser)
Today we will be working with a couple of different APIs to generate web pages.
last.fm: getting similar songs
In lecture, you saw examples of getting similar artists using the last.fm API. Today we will modify that code to extract similar tracks. The user supplies the artist name and the song name; an html page is generated containing similar songs.Here are two screenshots of examples.
Similar tracks to Ed Sheeran's Photograph:

Similar tracks to Fetty Wap's Trap Queen:
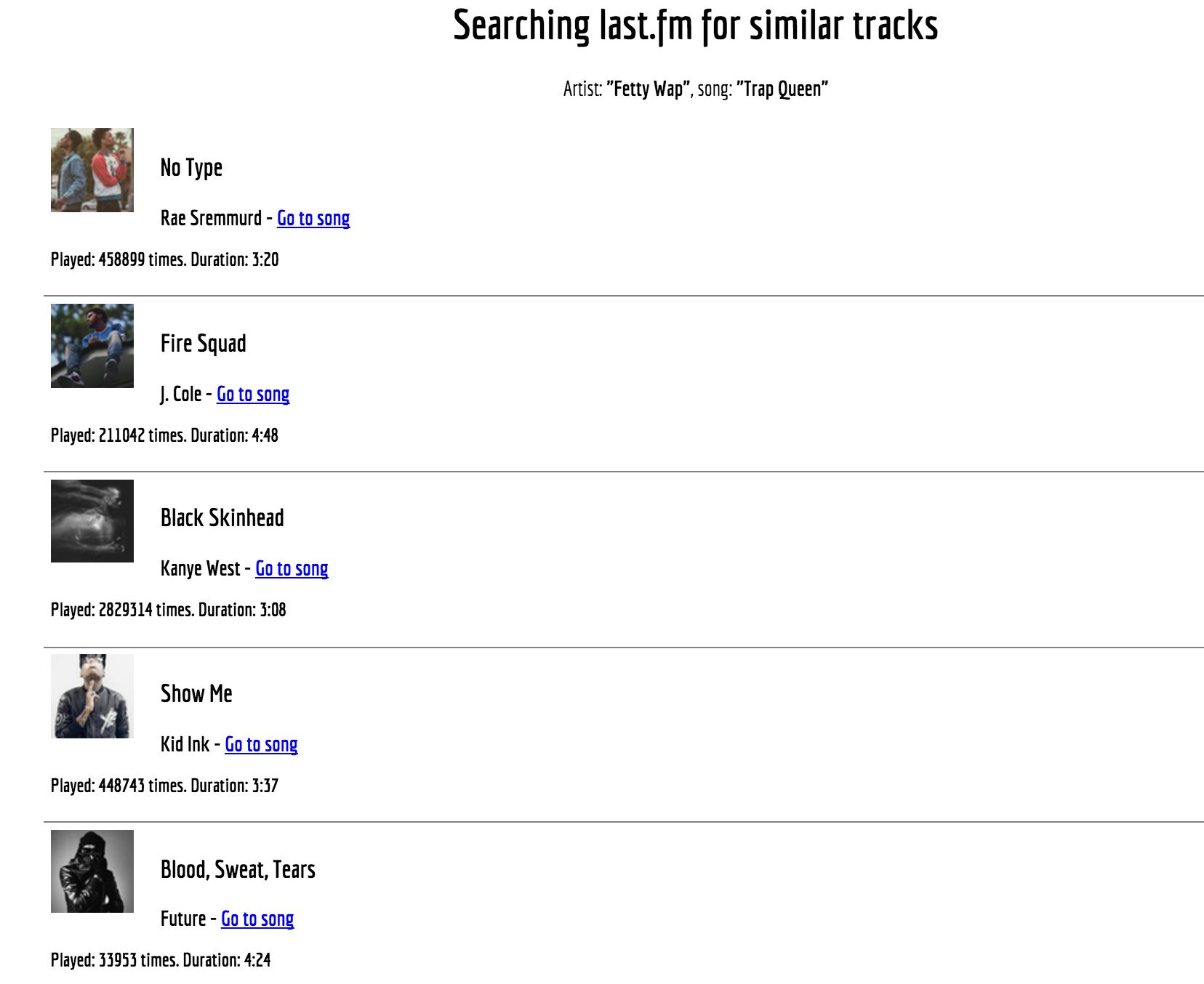
Task 0 last.fm: Review the steps to put all the pieces together
Look atsimilar_tracks.py and scroll down to the bottom. We'll break this code into separate tasks, as labeled below.
"""Puts together all the functions that are needed
to automatically generate HTML pages based on user input.
"""
Task 1: Getting user input artistName = raw_input('Enter the name of a favorite artist/band: ')
trackName = raw_input('Enter the name of a song from this artist: ')
Task 2: Getting http request content stringResponseFromAPI = requestSimilarTracks(trackName, artistName)
# These two lines are only for exploring the JSON response
# the first time
# jsonResponse = json.loads(stringResponseFromAPI)
# writeJSONforExploration(jsonResponse, 'similartracks.json')
if stringResponseFromAPI: # If there is a response (not None)
Task 3: Extracting relevant information from content trackDicts = extractTrackDicts(stringResponseFromAPI, 20)
Task 4: Create parameters to send to HTML template parametersForTemplate = {'query1': _______,
'query2': ______,
'tracksList': _______}
Task 5: Fill the holes in the HTML template htmlText = fillHTMLTemplate(__________, ____________)
Task 6: Create new HTML filename, write HTML page and view in browser filename = 'similar2'+ "".join(trackName.split()) + ".html"
writeHTMLFile(htmlText, ________)
openBrowserForHTMLFile(_______)
Task 1last.fm: Getting user input
Task 1: Getting user input artistName = raw_input('Enter the name of a favorite artist/band: ')
trackName = raw_input('Enter the name of a song from this artist: ')raw_input function here to get the user's input. Click here for documentation about raw_input. The user's inputs are stored in the variables artistName and trackName.
Task 2last.fm: Getting HTTP request content
Task 2: Getting http request content stringResponseFromAPI = requestSimilarTracks(trackName, artistName) similar_artists.py. Since we are looking for
similar tracks instead of similar artists, the code has a lot of overlap..
We only need to change 3 things, as indicated in yellow highlight below.
def requestSimilarArtists(artistName)1:
""" Prepares the request for the Web API.
Checks for what kind of response was received
and returns the 'content' part of the response.
"""
baseURL = "http://ws.audioscrobbler.com/2.0/"
httpResp = requests.get(baseURL,
params={'method': 'artist.getSimilar'2,
'format': 'json',
'api_key': '6b1628504240124aaf7abd282731010e',
'artist': artistName}
3)
if httpResp.status_code == 200:
print "We got a response from the API!"
return httpResp.content
else:
print "Request not fulfilled"
print httpResp.status_code, httpResp.reason, httpResp.text
- We are writing a method called
requestSimilarArtists, which takes an artist's name as a parameter. The last.fm API, which allows anyone to build their own programs using Last.fm data, will be used to obtain this data. The API root URL is located athttp://ws.audioscrobbler.com/2.0/ - There are many methods available in the last.fm API:
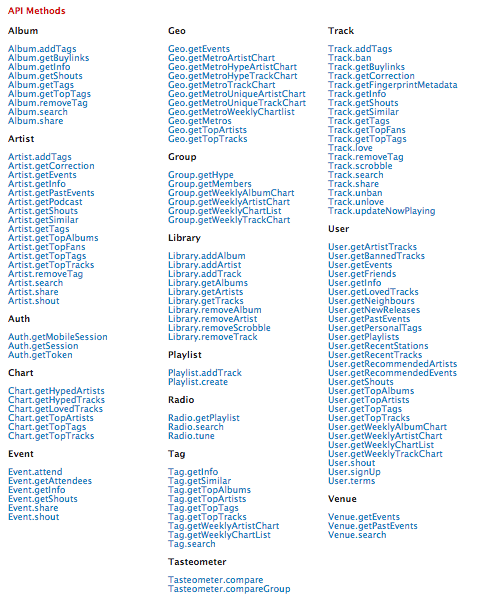
If you click on Artist.getSimilar, you will see what parameters are expected, sample response, possible errors, etc., which help you understand how to use the method.
- Notice that an
api_keyis specified in the code above. When working on your own, many of the web APIs will require you to apply for an account and/or a key to access the data. In CS111, we will always provide you with the URL and authentication needed.
Task 3last.fm: Extracting relevant data from response
Task 3: Extracting relevant information from content trackDicts = extractTrackDicts(stringResponseFromAPI, 20) similar_tracks.py at the template for
function extractTrackDicts. This is where we poke around and figure out what
data we have, and what we want to extract.
queryResult = json.loads(stringResponseFromAPI)
# provide empty dict in case we didn't get results
outerDict = queryResult.get('similartracks', {})
if 'track' in outerDict:
tracks = outerDict['track']
else:
tracks = []
tracks for our Fetty Wap/Trap Queen example?
type(tracks)
tracks is a list. What's in the list?
type(tracks[0])
tracks[0].keys()[u'streamable',
u'name',
u'artist',
u'url',
u'image',
u'mbid',
u'duration',
u'playcount',
u'match']
tracks[0] looks like this (remember
that the order of the keys above does not necessarily correlate to the
order of the items below):
{u'artist': {u'mbid': u'c78c3026-426b-4580-ab23-08490bb8b515',
u'name': u'Rae Sremmurd',
u'url': u'http://www.last.fm/music/Rae+Sremmurd'},
u'duration': 200,
u'image': [{u'#text': u'http://img2-ak.lst.fm/i/u/34s/e55005d515bc4923c975f5e2974b6715.png',
u'size': u'small'},
{u'#text': u'http://img2-ak.lst.fm/i/u/64s/e55005d515bc4923c975f5e2974b6715.png',
u'size': u'medium'},
{u'#text': u'http://img2-ak.lst.fm/i/u/174s/e55005d515bc4923c975f5e2974b6715.png',
u'size': u'large'},
{u'#text': u'http://img2-ak.lst.fm/i/u/300x300/e55005d515bc4923c975f5e2974b6715.png',
u'size': u'extralarge'},
{u'#text': u'http://img2-ak.lst.fm/i/u/e55005d515bc4923c975f5e2974b6715.png',
u'size': u'mega'},
{u'#text': u'http://img2-ak.lst.fm/i/u/arQ/e55005d515bc4923c975f5e2974b6715.png',
u'size': u''}],
u'match': 1.0,
u'mbid': u'bacc3a68-3614-40b9-b4fb-cafa32930d18',
u'name': u'No Type',
u'playcount': 458899,
u'streamable': {u'#text': u'0', u'fulltrack': u'0'},
u'url': u'http://www.last.fm/music/Rae+Sremmurd/_/No+Type'}
If you look carefully at the output above, you'll notice the following:- the
u'in front the strings stands for unicode - the value associated with the artist key is a dictionary
- the value associated with the image key is a list of dictionaries
- the list of dictionaries for the image key contains various sizes of images, ranging from small to mega (values for the key size).
- for each track, we want to extract this set of information (and store it in a dictionary):
- the artist name
- the track's duration (which we can convert using
convert_minutes) - the URL of the medium size image
- the title of the track
- the playcount of the track
- the url of the track
extractTrackDictswill return a list of such dictionaries for each similar track
extractTrackDicts -- you can use extractArtistDicts from lecture as a model.
To summarize: we have 3 different ways to explore the data that is returned from the web API:
- The variable
jsonResponsethat is created insimilar_tracks.pycan be analyzed in Canopy's interactive python pane. After your program works correctly, you can comment out the line of code. - The file
similarTracks.jsonis written to your current working directory, and you can open it directly in Canopy to examine its contents. After your program runs, you can comment out this line (no need to write the file anymore). - Typing this:
directly into a web browser displays the data to examine. Note thathttp://ws.audioscrobbler.com/2.0/?method=track.getSimilar&artist=Fetty%20Wap&track=Trap%20Queen&api_key=6b1628504240124aaf7abd282731010e%20is the ascii encoding for a space (see the%20between Fetty and Wap, and also between Trap and Queen).
Task 4last.fm: Focus on HTML template parameters
Task 4: Create parameters to send to HTML template parametersForTemplate = {'query1': ______,
'query2': _____,
'tracksList': _____}
similarTracksTemplate.py) that we will use to create the web
page.
Look
for {{query1}}, {{query2}} and
tracksList. These are the "holes" in the template that will be filled with the values supplied in the parametersForTemplate dictionary.
This block of HTML code: <body>
<h1>Searching last.fm for similar tracks</h1>
<p>Artist: <strong>"{{query1}}"</strong>, song: <strong>"{{query2}}"</p>

And this line of HTML:
{% for track in tracksList %}
Task 5last.fm: Fill holes in HTML template
Task 5: Fill the holes in the HTML
template htmlText = fillHTMLTemplate(_______, _______)similarTracksTemplate.py). The second blank should be
the variable that contains the dictionary of template parameters
defined in Task 4 above.
Task 6last.fm: Create HTML file name, write HTML page and view in browser
Task 6: Create new HTML filename, write HTML page and view in browser filename = 'similar2'+ "".join(trackName.split()) + ".html"
writeHTMLFile(htmlText, _________)
openBrowserForHTMLFile(_________) similar2TrapQueen.html, which is created via string concatentation and stored in the variable filename. It is this filename that we want to write as an HTML file, and also that we want to view in a browser (as shown below):
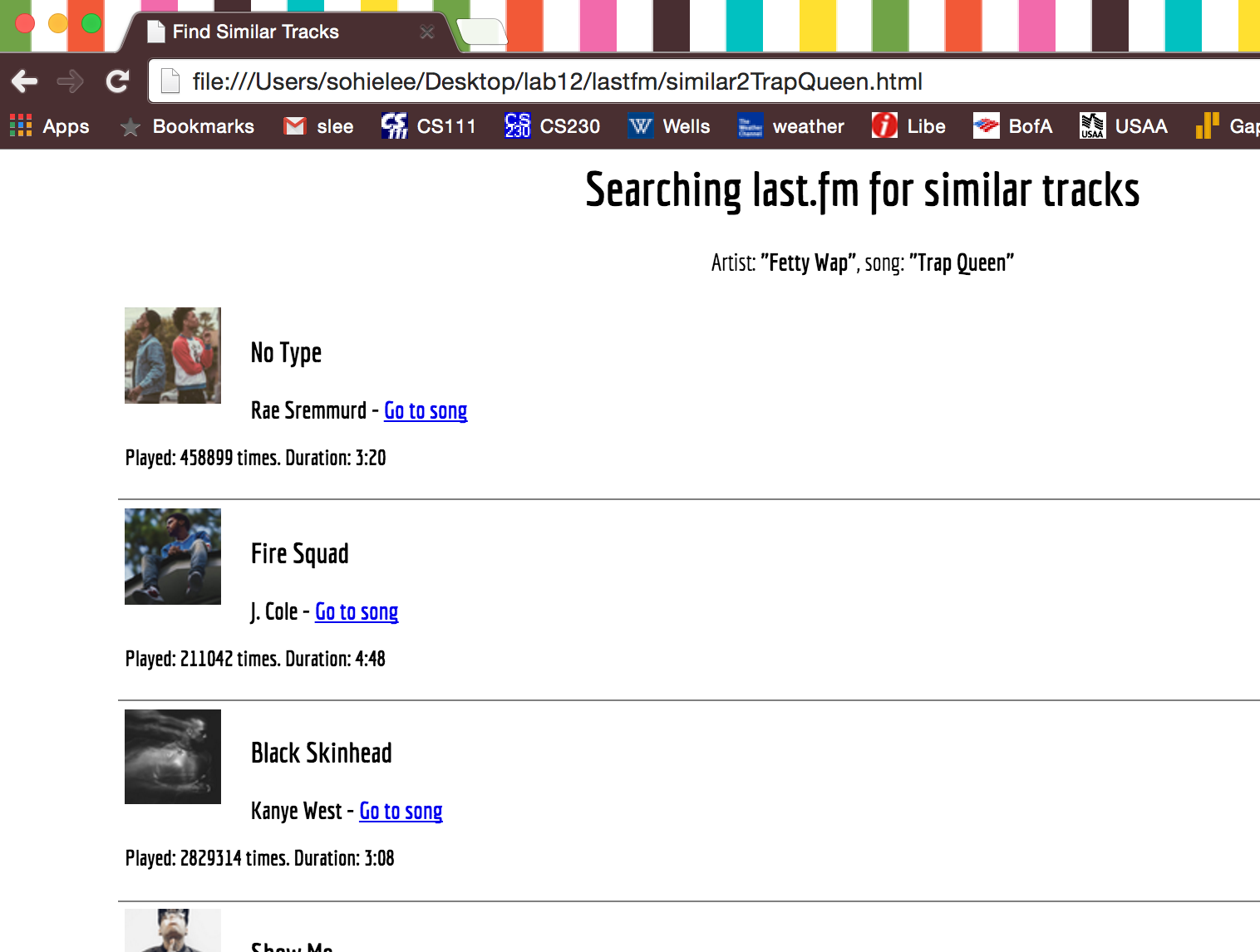
Task 7last.fm: Package all the pieces
into a main() function
Create a function to contain
all the testing (from asking for user input to displaying the generated HTML
page in a browser).
Task 8last.fm: Run your program several times with different values, test it out
A new task with a different API: Google maps directions
Generating step-by-step directions
In this task, your goal is to generate directions between two locations using the Google Maps Direction API. Today, we will only be generating text directions (no images). Here are two examples:Directions from Wellesley College to Boston Aquarium:

Directions from Stanford to the Ferry Building, San Francisco:

We are going to follow the same steps as we did above with the generating similar tracks using the last.fm api above, but this time with the Google Directions api.
Peek in your lab12_programs folder and open
the googlemaps subfolder. Note that there are 3 files in
there: direction.py, directionsTemplate.py
and style.css. The only file that you will edit
is direction.py. (directionsTemplate.py
contains the string with the HTML temlate with holes to be filled,
and style.css contains some basic styling for the HTML
page).
Task 0googlemaps: Start with the testing code
"""Puts together all the functions that are needed to automatically
generate HTML pages based on a user input.
"""
Task 1: Getting user input
start = raw_input('Enter the start location (e.g., Wellesley): ')
end = raw_input('Enter the end location (e.g., Boston): ')
Task 2: Getting http request content stringResponseFromAPI = requestDirections(start, end)
if stringResponseFromAPI: # If there is a response (not None)
Task 3: Writing json response out to file so we can examine it
jsonResponse = json.loads(stringResponseFromAPI)
writeJSONforExploration(jsonResponse, 'directions.json')
Task 4: Extracting relevant information from content resultsDict = extractDirectionsDict(stringResponseFromAPI)
Task 5: Fill the holes in the HTML template htmlText = fillHTMLTemplate(__________, ____________)
Task 6: Create new HTML filename, write HTML page and view in browser
filename = start +'_to_' + end + ".html"
writeHTMLFile(htmlText, ________)
openBrowserForHTMLFile(_______)
Task 1googlemaps: Getting user input
Task 1: Getting user input
start = raw_input('Enter the start location (e.g., Wellesley): ')
end = raw_input('Enter the end location (e.g., Boston): ')
Task 2googlemaps: Getting http request content
Task 2: Getting http request content stringResponseFromAPI = requestDirections(start, end)requestDirections until it makes sense to you before proceeding to the next task.
Task 3googlemaps: Writing python value content to file (so we can look at it closely)
Task 3: Writing json response out to file so we can examine it
jsonResponse = json.loads(stringResponseFromAPI)
writeJSONforExploration(jsonResponse, 'directions.json')- New file option. A new file is created
called
directions.jsonthat contains the python value. Open this file in Canopy and take a careful look at it, try to decipher the format and contents. - Interactive python option. Notice that the variable
jsonResponsecontains the string generated from the API. You can usetype(jsonResponse)in Canopy's interactive pane and see if things are lists or dictionaries, and work forward from there.
The variable jsonResponse will look something like this (this is with starting location "Wellesley College" and ending location "Boston Aquarium"):
{u'geocoded_waypoints': [{u'geocoder_status': u'OK',
u'place_id': u'ChIJWTIuyMOG44kRbJjPcVAX_uw',
u'types': [u'bus_station',
u'transit_station',
u'point_of_interest',
u'establishment']},
{u'geocoder_status': u'OK',
u'place_id': u'ChIJsz-sxodw44kRQtFaDLO7Ipk',
u'types': [u'subway_station',
u'transit_station',
u'point_of_interest',
u'establishment']}],
u'routes': [{u'bounds': {u'northeast': {u'lat': 42.3617418,
u'lng': -71.0503918},
u'southwest': {u'lat': 42.2936206, u'lng': -71.3172155}},
u'copyrights': u'Map data \xa92015 Google',
u'legs': [{u'distance': {u'text': u'19.6 mi', u'value': 31548},
u'duration': {u'text': u'34 mins', u'value': 2063},
u'end_address': u'Aquarium, 183 State St, Boston, MA 02110, USA',
u'end_location': {u'lat': 42.3596503, u'lng': -71.0515472},
u'start_address': u'Wellesley College, Wellesley, MA 02481, USA',
u'start_location': {u'lat': 42.2936206, u'lng': -71.30763329999999},
u'steps': [{u'distance': {u'text': u'197 ft', u'value': 60},
u'duration': {u'text': u'1 min', u'value': 17},
u'end_location': {e u'lat': 42.29413599999999, u'lng': -71.307407},
u'html_instructions': u'Head north toward College Rd',
u'polyline': {u'points': u'cncaGtgfrLk@Qa@OICOE'},
u'start_location': {u'lat': 42.2936206, u'lng': -71.30763329999999},
u'travel_mode': u'DRIVING'},
{u'distance': {u'text': u'0.2 mi', u'value': 283},
u'duration': {u'text': u'1 min', u'value': 57},
u'end_location': {u'lat': 42.2961114, u'lng': -71.3090142},
u'html_instructions': u'Turn left onto College Rd',
u'maneuver': u'turn-left',
u'polyline': {u'proints': u'kqcaGhffrLIh@M`@a@n@c@d@]b@gApBSJA@I@G@G@IAg@GQCEAkAB'},
u'start_location': {u'lat': 42.29413599999999, u'lng': -71.307407},
u'travel_mode': u'DRIVING'},
...
type(jsonResponse)- if it's a dictionary, look at the keys() and values()
- if it's a dictionary, what are the values for the various keys? Are they strings, lists, dictionaries?
- if you encounter a list, look at the first few items of the list and determine their type (use
[:]notation, eg[:5] for 1st 5,[0]for 1st element, etc).) - This google maps directions guide gives a good explanation of routes/steps/legs
Task 4googlemaps: Complete extractDirectionsDict
Task 4: Extracting relevant information from content resultsDict = extractDirectionsDict(stringResponseFromAPI)extractDirectionsDict.
Specifically, we are interested in the following:
- routes (if there is more than 1 route, take the first one)*
- legs (if there is more than one leg, take the first one)*
- distance
- duration
- startPoint
- endPoint
- steps (iterate through each step in the steps)
- html_instructions (this is what gets printed to get us from start to finish)
extractDirectionsDict
Task 5googlemaps: Fill in the holes in the HTML template
Task 5: Fill the holes in the HTML template htmlText = fillHTMLTemplate(__________, ____________)directionsTemplate.py. The second blank should be
the variable that contains the dictionary created by extractDirectionsDict
defined in Task 4 above.
Task 6googlemaps: Create HTML file name, write HTML page and view in browser
Task 6: Create new HTML filename, write HTML page and view in browser
filename = start +'_to_' + end + ".html"
writeHTMLFile(htmlText, ________)
openBrowserForHTMLFile(_______)
Wellesley College_to_Boston Aquarium.html, which is created via string
concatentation and stored in the variable filename. It is
this filename that we want to write as an HTML file, and also that we
want to view in a browser. The spaces appear in the file name because
spaces were used in the user-provided start and end locations.
Task 7googlemaps: Package all the pieces
into a main() function
Create a function to contain
all the testing (from asking for user input to displaying the generated HTML
page in a browser).
Task 8googlemaps: Run your program several times with different values, test it out
Try lots of different locations, like your home address, or your favorite city, restaurant, venue, etc.
Task 9:googlemaps: A note about style and font options
- You may have noticed there's a bit of
formatting in this web page. We are using a style sheet
called
style.csswhich is in yourlab12_programsfolder. It contains (simple) style rules for the page. Here is a good CSS tutorial if you'd like to make prettier web pages. - You'd prefer a different font? No problem. Follow these steps:
- Choose a google font that you like from this page (let's say you select the font "Anton")
- edit line 6 of
directionsTemplate.pyand replace "Oxygen" with the name of your chosen font (Anton) - edit line 9 of
style.cssand replace 'Oxygen' with the name of your chosen font (Anton) - restart your python kernel in Canopy, and then re-run
directions.pyto see your new font in the generated web page - if the font doesn't change, try deleting the
directionsTemplate.pycfrom your folder and re-runningdirections.py