Reading/Resources
- Think Python, Chapter 11: Dictionaries
- Python documentation on dictionaries
- Python documentation on dictionary operations
- matplotlib gallery
- matplotlib plotting commands
- matplotlib examples
About this Problem Set
This problem set is intended to give you practice with:
- Creating and manipulating dictionaries
- More sophisticated use of string methods, reading files, list comprehension, sorting, etc.
- Creating charts with the matplotlib package
There are only two tasks in this Problem Set.
All code for this assignment is available in the ps06_programs folder in the cs111/download directory within your cs server account.
This problem set will be graded using this grade sheet.
Task 1: Unjumbler
This is a solo problem which you must complete on your own, with no help.
Word Jumble is a popular game that appears in many newspapers and online. The game involves "unjumbling" English words whose letters have been reordered. For instance, the jumbled word ytikt can be unjumbled to kitty. Here is one version of the online game.

In this problem, you will create a Python program that is able to successfully unjumble jumbled words. Your program will start with a file of English words. For each word in the file, it will convert that word to an unjumble key by sorting the lowercase versions of the characters of the word in alphabetical order. For instance, the unjumble key for 'regal' would be 'aeglr'. It will create an unjumble dictionary that associates each such unjumble key with a list of all words that have the same unjumble key. For example, the unjumble dictionary will associate the unjumble key 'aeglr' with the list of words ['glare', 'lager', 'large', 'regal']. Finally, to unjumble a string you simply convert it to its unjumble key and look that up in the unjumble dictionary. For example, to unjumble 'rgael', you convert it to its key 'aeglr', and look this up in the unjumble dictionary to find that it unjumbles to any of the words in the list ['glare', 'lager', 'large', 'regal'].
To complete this task, you will need to define the following four functions
in the file unjumble.py, which you will create inside the Unjumbler folder within the
ps06_programs folder available from the download directory on the cs server.
In this and subsequent assignments, you should simplify your code by using list comprehensions and dictionary comprehensions instead of loops when they are appropriate. Not every loop can be replaced by comprehensions, but many can.
unjumbleKeytakes a single argument, a string, and returns a string that is the unjumble key of its input --- i.e., a string consisting of the lowercase versions of all all characters of the string in alphabetical order. For example,In[1]: unjumbleKey('argle')
Out[1]: 'aeglr'
In[2]: unjumbleKey('regal')
Out[2]: 'aeglr'
In[3]: unjumbleKey('Star')
Out[3]: 'arst'
In[4]: unjumbleKey('histrionics')
Out[4]: 'chiiinorsst'
Notes:
- When applied to a string, the
sortedfunction returns a list of the characters in sorted order:In[4]: sorted('abracadabra')
Out[4]: ['a','a','a','a','a','b','b','c','d','r','r']
- The
joinmethod of string values can be used to glue a list of strings together, using the string to whichjoinis applied as a separator.In[5]: ':'.join(['bunny','cat','dog'])
Out[5]: 'bunny:cat:dog'
In[6]: ' '.join(['bunny','cat','dog'])
Out[6]: 'bunny cat dog'
In[7]: ''.join(['bunny','cat','dog'])
Out[7]: 'bunnycatdog'
- When applied to a string, the
makeUnjumbleDictionarytakes a single argument, the name (a string) of a wordlist file that has one word per line, and returns a dictionary that associates the unjumble key of every word in the wordlist with the list of all words with that unjumble key. All words in the same list are anagrams --- i.e., words that all have exactly the same letters (including repeated ones), but in different orders.The
Unjumblerfolder in theps06_programsfolder contains three wordlist files:tinyWordList.txt(33 words),mediumWordList.txt(45,425 words), andlargeWordList.txt(438,712 words), For example, the filetinyWordList.txtcontains the following words:alerting altering arts caster caters crates glare histrionics integral lager large rats reacts recast regal relating restrain retrains opts post pots spot star strainer stop tars terrains traces triangle trichinosis tops tsar
The invocation of
makeUnjumbleDictionaryon this file should return a dictionary with 7 key/value items:In[8]: tinyUnjumbleDict = makeUnjumbleDictionary('tinyWordList.txt')
In[9]: tinyUnjumbleDict
Out[9]:
{'acerst':['caster','caters','crates','reacts','recast','traces'],
'aegilnrt':['alerting','altering','integral','relating','triangle'],
'aeglr':['glare','lager','large','regal'],
'aeinrrst':['restrain','retains','strainer','terrains','trainers'],
'arst':['arts','rats','star','tars','tsar'],
'chiiinorsst':['histrionics','trichinosis'],
'opst':['opts','post','pots','spot','stop','tops']}
Notes:
- You have already learned how to read wordlists from a file. Using a helper function is always a good idea for keeping your code modular. Don't forget to close an open file.
- In order to check if a key
kis in a dictionaryd, use the expressionk in dand notk in d.keys(). The latter expression creates a new list of keys every time it is evaluated, and can cause extremely slow behavior for large word lists. For more details, see the note on this in the CS111 Google group. - Something else to avoid in this function is nested loops or nested list and/or dictionary
comprehensions. In order for
makeUnjumbleDictionaryto work on large word lists, you want to process each word in the word list exactly once. But if you have an inner loop or comprehension that processes the all the words in the word list for each outer loop or comprehension, this will almost certainly result in a function that cannot handle anything other than small word lists. - In this problem, it is recommended that you use explicit loops rather than list or dictionary comprehensions in order to understand more easily how much work you are doing for each word in the wordlist.
unjumbletakes an unjumble dictionary (created bymakeUnjumbleDictionary) and a string and returns a list of all words in the dictionary to which the input string unjumbles. If there are no such words, it returns the empty list. For example,In[11]: tinyUnjumbleDict = makeUnjumbleDictionary('tinyWordList.txt')
In[12]: unjumble(tinyUnjumbleDict, 'argle')
Out[12]: ['glare','lager','large','regal']
In[13]: unjumble(tinyUnjumbleDict, 'arst')
Out[13]: ['arts','rats','star','tars','tsar']
In[14]: unjumble(tinyUnjumbleDict, 'foobar')
Out[14]: []
-
mostAnagramstakes an unjumble dictionary (created bymakeUnjumbleDictionary) and returns the longest anagram list in the dictionary. This is the list of all the anagrams of the words with the most anagrams in the dictionary. If more than one list has the same length, it should return one of the lists (it doesn't matter which).For example,
mostAnagrams(tinyUnjumbleDict)should return one of the following two lists:['caster','caters','crates','reacts','recast','traces']['opts','post','pots','spot','stop','tops']
For full credit,
mostAnagramsmust use a list comprehension over the keys and values of the unjumble dictionary.Hint: Remember that
maxreturns the largest item in a list -- this is also applicable to lists of tuples. It first checks for the max of the items in the 0th indices in the tuples, and in case of ties, for the items in the 1st index, and so on. For example:In [15]: max([(3, 'w'), (4, 'x'), (4, 'y'), (1, 'z')])
Out [15]: (4, 'y')In addition to defining the
mostAnagramsfunction, use this function to determine the longest list of anagrams in largeWordList.txt, and include this list in a comment at the bottom of yourunjumble.pyfile..
For fun, use your unjumble function as an assistant in playing
the online game.
Task 2: A Titanic Task
This task (and only this task) is a partner problem in which you are required to work with a partner as part of a two-person team.
In this task, you will analyze data about passengers from the Titanic, a large ship that tragically sank in the waters of the North Atlantic Ocean in 1912. Passenger data can be found in the titanic.txt file provided
in the ps06_programs/Titanic folder.
Study the structure of the data in titanic.txt before you begin.
In this and subsequent assignments, you should simplify your code by using list comprehensions and dictionary comprehensions instead of loops when they are appropriate. Not every loop can be replaced by comprehensions, but many can.
Task 2a: Passenger Lists
To begin, create a new file titanic.py
in ps06_programs/Titanic and define the following four functions
(and possibly additional helper functions) in this file:
getKey:def getKey(s): '''Returns that portion of string s to the left of the first equal sign, with flanking white space removed.'''
Example input/output:
In[20]: getKey(' class=3rd Class')
Out[20]: 'class'
In[21]: getKey(' age=28.0 ')
Out[21]: 'age'
getValue:def getValue(s): '''Returns that portion of string s to the right of the first equal sign, with flanking white space removed.'''
Example input/output:
In[22]: getValue(' class=1st Class')
Out[22]: '1st Class'
In[23]: getValue(' job=Saloon Steward\n')
Out[23]: 'Saloon Steward'
- The above two functions will be used by the
passengerDictionaryFromLinefunction:def passengerDictionaryFromLine(line): '''Given a line describing a passenger from the Titanic database, returns a dictionary of information about this passenger. Each such dictionary has possible keys "name", "status" (survivor or victim), "age", "class", and "job", whose values contain information about the passenger. For example, for the line "Miss Eugenie Baclini (survivor); age=3.0; class=3rd Class" the returned dictionary would be: {'name': 'Miss Eugenie Baclini', 'status': 'survivor', 'age': '3.0', 'class': '3rd Class'} For the line "Mr Ernest Owen Abbott (victim); age=21.0; class=Victualling; job=Lounge Pantry Steward" the returned dictionary would be: {'name': 'Mr Ernest Owen Abbott', 'status': 'victim', 'age': '21.0', 'class': 'Victualling', 'job': 'Lounge Pantry Steward'} For the line 'Master Georges Youssef ("George Thomas") Touma (survivor); age=8.0; class=3rd Class\n' the returned dictionary would be: {'age': '8.0', 'class': '3rd Class', 'name': 'Master Georges Youssef ("George Thomas") Touma', 'status': 'survivor'} Note that not every line has every key. For example, two of the above three lines do not have a job field, and so the resulting dictionaries do not contain the key "job". Also note that the first component of a line may contain parentheses other than the ones in "(survivor)" or "(victim)". Finally, note that this function should work correctly whether or not the given line ends in a newline.'''
Example input/output:
In [41]: passengerDictionaryFromLine("Miss Eugenie Baclini (survivor); age=3.0; class=3rd Class")
Out[41]:
{'age': '3.0',
'class': '3rd Class',
'name': 'Miss Eugenie Baclini',
'status': 'survivor'}
In [42]: passengerDictionaryFromLine("Mr Ernest Owen Abbott (victim); age=21.0; class=Victualling; job=Lounge Pantry Steward")
Out[42]:
{'age': '21.0',
'class': 'Victualling',
'job': 'Lounge Pantry Steward',
'name': 'Mr Ernest Owen Abbott',
'status': 'victim'}
In [43]: passengerDictionaryFromLine('Master Georges Youssef ("George Thomas") Touma (survivor); age=8.0; class=3rd Class\n')
Out[43]:
{'age': '8.0',
'class': '3rd Class',
'name': 'Master Georges Youssef ("George Thomas") Touma',
'status': 'survivor'} - The
passengerDictionaryFromLinefunction will be used by thecreateListOfTitanicPassengersfunction:
Note that not every dictionary will have all fields. The Baclini dictionary does not have a job field, for instance.def createListOfTitanicPassengers(fileName): '''Returns a list of passenger dictionaries, where each element of the list is created by calling passengerDictionaryFromLine on a line from the specified file.'''
Example input/output:
In [24]: passengerList = createListOfTitanicPassengers('titanic.txt')
In [25]: len(passengerList)
Out[25]: 2208
In[26]: passengerList[2168]
Out[26]:
{'age': '31.0',
'class': '1st Class',
'group': 'Servant',
'job': 'Personal Maid',
'name': 'Miss Helen Alice Wilson',
'status': 'survivor'}
In[27]: passsengerList[254]
Out[27]:
{'age': '30.0',
'class': 'Engine',
'job': 'Trimmer',
'name': 'Mr Henry ("Harry") Brewer',
'status': 'victim'}Notes:
- 36 out of the 2208 lines in the file
titanic.txtcontain multiple parentheses besides the parenthetical information labeling people as survivors and victims. Your code should handle these lines appropriately. For example:Master Georges Youssef ("George Thomas") Touma (survivor); age=8.0; class=3rd ClassThe corresponding dictionary for this line should be:
In[27]: passengerList[2018]
Out[27]: {'age': '8.0',
'class': '3rd Class',
'name': 'Master Georges Youssef ("George Thomas") Touma',
'status': 'survivor'} - The following tasks assume that the global variable
passengerListis defined to be a list of all the passenger dictionaries created from the filetitanic.txt.passengerList = createListOfTitanicPassengers('titanic.txt')
- 36 out of the 2208 lines in the file
Task 2b: Job Frequency
Define the following function:
def topJobs(num, passengers): '''Assume that num is a nonnegative integer and passengers is a list of passenger dictionaries. Returns a list of num pairs of the form (jobName, jobFrequency), where jobName is the name of a job and jobFrequency is the number of passengers with that job. These pairs should be the top num most popular jobs, sorted by frequency from highest to lowest. If num is greater than the total number of jobs, a list of all job pairs should be returned. Some passenger dictionaries have no jobs; these should not be included in the results.'''
Here are sample invocations involving topJobs:
In[28]: topJobs(25, passengerList)
Out[28]:
[('General Labourer', 161),
('Fireman', 161),
('Saloon Steward', 123),
('Trimmer', 73),
('Farm Labourer', 49),
('Farmer', 48),
('Bed Room Steward', 46),
('Steward', 44),
('Greaser', 33),
('Able Seaman', 29),
('Servant', 28),
('Businessman', 25),
('Personal Maid', 21),
('Stewardess', 18),
('Seaman', 18),
('Waiter', 17),
('Assistant Waiter', 17),
('Scullion', 14),
('Miner', 14),
('Carpenter / Joiner', 14),
('Baker', 14),
('Leading Fireman', 13),
('Of Independent Means', 12),
('Assistant Saloon Steward', 12),
('Engineer', 11)]
In[29]: len(topJobs(2500, passengerList))
In[29]: 300
Notes:
- Review Slides 9-18 through 9-22 on sorting for this subtask.
To simplify grading of this task,
titanic.pyshould include the following invocations for this task:print 'topJobs(25, passengerList) =>', topJobs(25, passengerList), '\n' print 'len(topJobs(2500, passengerList)) =>', len(topJobs(2500, passengerList)), '\n'
Note that when
printis used on the resulting list, it will be formatted differently.
Task 2c: Cabin Class Survival Dictionaries
Define the following function:
def createSurvivalDictionary(passengers): '''Given a list of passenger dictionaries, returns a dictionary whose keys are all the cabin classes that appear in passengers. The value associated with the cabin class name in this resulting dictionary should itself be another dictionary that has three key/value pairs: (1) The key "survivors" maps to the number of survivors in that cabin class; (2) The key "victims" maps to the number of victims in that cabin class; (3) The key "survivalRate" maps to the survival rate in that cabin class (a floating point number rounded to 3 decimal digits)'''
Example input/output:
In[30]: createSurvivalDictionary(passengerList)
Out[30]:
{'1st Class': {'survivalRate': 0.62, 'survivors': 201, 'victims': 123},
'2nd Class': {'survivalRate': 0.418, 'survivors': 119, 'victims': 166},
'3rd Class': {'survivalRate': 0.254, 'survivors': 180, 'victims': 528},
'A la Carte': {'survivalRate': 0.043, 'survivors': 3, 'victims': 66},
'Deck': {'survivalRate': 0.652, 'survivors': 43, 'victims': 23},
'Engine': {'survivalRate': 0.222, 'survivors': 72, 'victims': 253},
'Victualling': {'survivalRate': 0.218, 'survivors': 94, 'victims': 337}}
Notes:
- One approach is to first find all the cabin classes, then make a dictionary
that associates each cabin class with the mini-dictionary
{'survivors': 0, 'victims': 0}, and then iterate through the passenger list updating the mini-dictionary for the cabin class of each passenger. Once all the passengers have been processed, the correct survivalRate can be added to each mini-dictionary based on the number of survivors and victims. - In Python, the name
classis a special keyword, so don't use it as a variable name. - To simplify the grading of this task,
titanic.pyshould include the following invocation for this task:print 'createSurvivalDictionary(passengerList) => ', createSurvivalDictionary(passengerList), '\n'
Note that when print is used on the resulting dictionary, the key/value pairs will be
formatted differently and in a different order.
Task 2d: Horizontal Bar Chart of Survival Rates by Class
Implement the following two functions so that the invocation
of barChartOfSurvivalRates(passengerList) will cause a
horizontal bar chart to be displayed showing the percentage of
survivors by cabin class, in decreasing order by survival rate..
def barChartOfPercentages(tuples, chartTitle, xtitle, ytitle): '''Given an (unsorted) list of tuples, each containing a percentage (a floating point value between 0.0 and 1.0) and a string, generates a horizontal bar chart, where the highest percentages are shown at the top and others follow in decreasing order. The chartTitle, xtitle, and ytitle are used for labeling the graph. The strings of the tuples are used as ytick labels.''' def barChartOfSurvivalRates(passengers): '''Given a list of passenger dictionaries, displays a horizontal bar chart of the sorted percentage of survival rates for each cabin class.'''
Note: You should use createSurvivalDictionary from Task 2c
as a helper function in the definition of barChartOfSurvivalRates(passengers).
Our solution generates the bar chart below. You are free to use different styling to display the information, as long as you fulfill the major requirements.
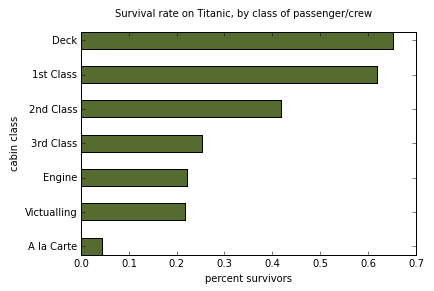
To simplify the grading of this task,
titanic.py should include the invocation
barChartOfSurvivalRates(passengerList)
so that it generates the bar chart when the file is run
in Canopy.
Task 2e: Pie Chart of Victims' Cabin Classes
Implement the following two functions so that the
invocation pieChartOfVictimsCabinClasses(passengerList)
will cause a pie chart to be displayed showing the relative number of
Titanic victims from each cabin class.
def pieChartFromOccurrenceDictionary(occDict): '''Assume occDict is an occurrence dictionary maps labels (strings) to occurrences (nonnegative integers). Displays a pie chart illustrating the relative number of occurrences for each label. Pie slices should be labeled by the labels, and ordered clockwise from smallest pie slice to largest pie slice starting at 12 o'clock.''' def pieChartOfVictimsCabinClasses(passengers): '''Given a list of passenger dictionaries, displays a pie chart showing the relative number of victims from each cabin class.'''
The following chart is the one generated by our solution.
When you first create your pie chart it may not look like this. In order
to get full credit, you'll need to add some more lines of code to get the slices
ordered by size and use the startangle parameter with the pie
function.
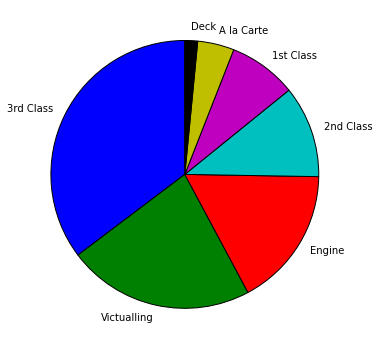
Notes:
- You should use
createSurvivalDictionaryfrom Task 2c as a helper function in the definition ofpieChartOfVictimsCabinClasses. - Use the statement
figure(1, figsize=(6,6), facecolor='white')before the call topiein order to get a circular pie instead of an oval pie. - To simplify grading of this task,
titanic.pyshould include the invocationpieChartOfVictimsCabinClasses(passengerList)so that it generates the pie chart when the file is run in Canopy.
Task 2f: Bar Graph of Survivors' Ages
Define the following four functions so that the invocation barChartOfSurvivorsAges(passengerList, n) will display a vertical bar chart showing the number of Titanic survivors in each of n equally sized age groups.
def getListOfSurvivorsAges(passengers): '''Given a list of passenger dictionaries, returns a new list consisting of the ages of all the survivors. For example, if there were three survivors aged 25.0, then three of the entries in the returned list should have value 25.0. Note that the returned list is a list of floating point numbers, not strings.''' def histogram(data, numberOfBins): '''Assume data is a list of non-negative floating point numbers and numberOfBins is the number of equal-sized bins in which to partition the numbers. Define the "data width" of the data to be one more than the maximum data element. Then each of the equally-sized bins has a bin width that is the data width divded by numberOfBins. Assume these bins are indexed from 0 to (numberOfBins - 1). Then the histogram function returns a new list whose length is numberOfBins and whose ith slot contains the number of data elements in the ith bin. For example, suppose L is the list [8.0, 19.0, 3.0, 6.0, 12.0, 7.0]. The data width of L is 20.0. If numberOfBins is 1, then this one bin covers the half-open interval [0.0, 20.0) and contains all 6 elements from the list. (In the half-open interval notation [lo, hi), the interval ranges from lo up to, but not including, hi.) So the result of histogram (L, 1) is [6]. If numberOfBins is 2, then there are two bins, each with bin width 10.0. The bin at index 0 covers the half-open interval [0.0, 10.0), which contains the 4 numbers 8.0, 3.0, 6.0, and 7.0, and the bin at index 1 covers the half-open interval [10.0, 20.0), which contains the two numbers 19.0 and 12.0. So the result of histogram(L, 2) is [4, 2]. If numberOfBins is 3, there are three bins, which cover half-open intervals [0, 6.66), [6.66, 13.33), and [13.33, 20) that contain 2, 3, and 1 elements from the list, respectively. So the result of histogram(L, 3) is [2, 3, 1]. In a similar fashion, * histogram(L, 4) results in the list [1, 3, 1, 1]. * histogram(L, 5) results in the list [1, 2, 1, 1, 1]. * histogram(L, 6) results in the list [1, 1, 2, 1, 0, 1] * histogram(L, 7) results in the list [0, 1, 3, 0, 1, 0, 1] ''' def barChartOfHistogram(hist, maximum, chartTitle, xtitle, ytitle): '''Given a list corresponding to a histogram for a set of data and given the maximum value of the data, displays a vertical bar chart of the histogram. The chart has the specified title. X-axis labels corresponding to the interval ranges of the histogram are optional.''' def barChartOfSurvivorsAges(passengers, numberOfAgeGroups): '''Given a list of passenger dictionaries, displays a vertical bar chart that illustrates the number of survivors in each of the given number of equally-sized age groups.'''
Below is a possible solution for how the bar chart of the histogram may look like, if we set the number of age groups to 5. Your final histogram should show the distribution for the argument 12 instead of 5.
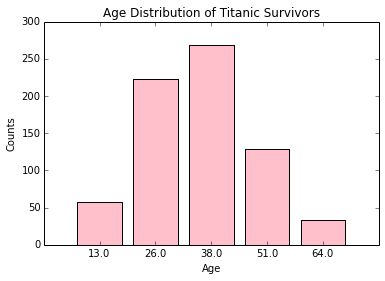
Notes:
-
Although the
histogramfunction has a complex specification, it has a simple implementation based on the following observation: given a floating point data widthdataWidthand the number of binsnumberOfBins, the bin widthbinWidthisdataWidth/numberOfBins, and you can easily calculate the bin index of of any numberdatumvia the formulaint(datum/binWidth). In the example where L is the list[8.0, 19.0, 3.0, 6.0, 12.0, 7.0],dataWidthis 20.0. IfnumberOfBinsis 4,binWidthis 5.0, and- 8.0 is in bin with index int(8.0/5.0) = 1,
- 19.0 is in bin with index int(19.0/5.0) = 3
- 3.0 is in bin with index int(3.0/5.0) = 0
- 6.0 is in bin with index int(6.0/5.0) = 1
- 12.0 is in bin with index int(12.0/5.0) = 2
- 7.0 is in bin with index int(7.0/5.0) = 1
To generate a result based on this observation, we can initialize the result list to contain
numberOfBinselements that are all 0, and then use the index information calculated above to increment the result list at this index. For example, whennumberOfBinsis 4, we initialize the result list to[0, 0, 0, 0], and then- After 8.0 is processed, the result list becomes
[0, 1, 0, 0](because 8.0 is at bin index 1); - After 19.0 is processed, the result list becomes
[0, 1, 0, 1](because 19.0 is at bin index 3); - After 3.0 is processed, the result list becomes
[1, 1, 0, 1](because 19.0 is at bin index 0); - After 6.0 is processed, the result list becomes
[1, 2, 0, 1](because 6.0 is at bin index 1); - After 12.0 is processed, the result list becomes
[1, 2, 1, 1](because 6.0 is at bin index 2); - After 7.0 is processed, the result list becomes
[1, 3, 1, 1](because 6.0 is at bin index 1);
At this point, all data have been processed, and the final result list is the correct answer for the
histogramfunction. - To simplify grading of this task,
titanic.py, should include the invocationbarChartOfSurvivorsAges(passengerList, 12)so that it generates the bar chart when the file is run in Canopy.
How to turn in
You must submit both soft-copy (electronic) and hard-copy (printed) versions of your problem set.
Soft-copy submission
Save your unjumble.py file in the Unjumbler folder.
One and only one
member of your team should submit your titanic.py file in the Titanic folder.
Submit the entire ps06_programs folder (renamed to yourname_ps06_programs) to your drop folder on the cs server using Fetch (for Macs) or WinSCP (for PCs).
You should submit this softcopy folder by
11:59pm on Mon. Oct. 19.
Hard-copy submission
Print out unjumble.py. It should include, as a comment at the
- end of the file, the
- answer for the longest list of anagrams in largeWordList.txt.
- Do not print out the text files containing the word lists.
One and only one member of your
team should submit titanic.py with the names of
both partners at the top.
Staple these pages together with a cover page, and submit this hardcopy package in class on Tue. Oct. 20. The hardcopy files must exactly match the softcopy files submitted the previous night.
Types of Tasks
Solo Problem
Task 1 is a solo problem, which means that you must do this task completely on your own, without any assistance from the CS111 staff, and without talking about it to your classmates. (You may ask the staff to clarify the instructions of a solo problem, but you cannot ask for help in solving the solo problem. You can talk to staff members about similar problems from lecture or lab.)
Partner Problem
On Task 2 (and only Task 2), you are required to work with a partner as part of a two-person team and you may work with someone that you have previously worked with, but you may not work with the same person for two consecutive psets. Your team will submit a single hardcopy of your team-solution to Task 2 and the same grade will be given to both team members for Task 2.
All work by a team must be a true collaboration in which members actively work together on all parts of the Task. The only work that you may do alone is talking with the instructors and drop-in tutors. Use this shared Google Doc to find a programming partner, and record who your partner is.